SOTA Paper Recommendation

Cosmos-Transfer1: Conditional World Generation with Adaptive Multimodal Control
SOTA Review
For a world model with strong generalization ability, I think the key point is still simulation data.
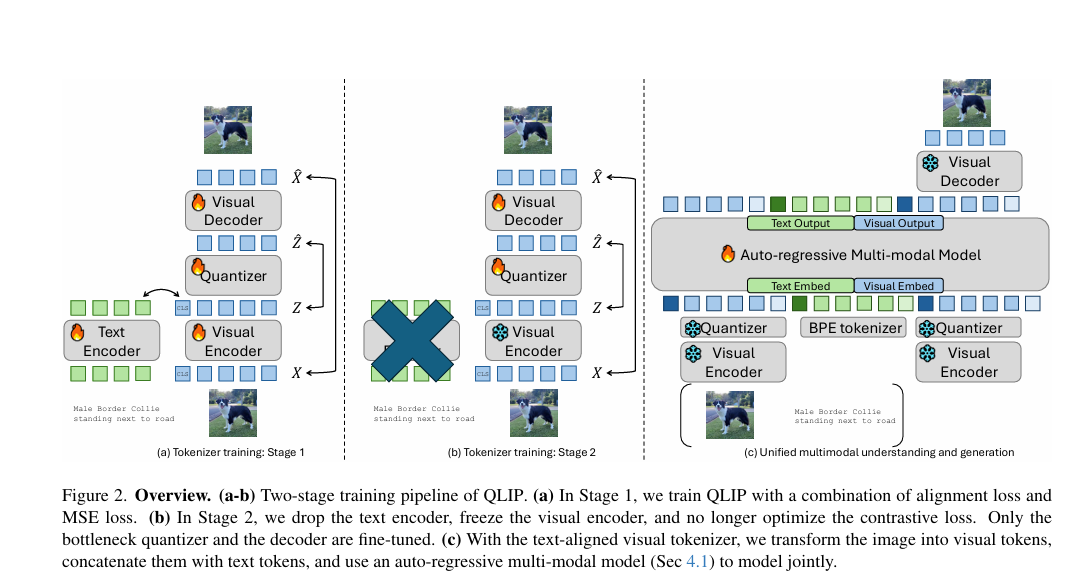
QLIP: Text-Aligned Visual Tokenization Unifies Auto-Regressive Multimodal Understanding and Generation
Purshow Review
Training a "unify encoder" by jointly reconstructing and aligning is a very important and interesting way.
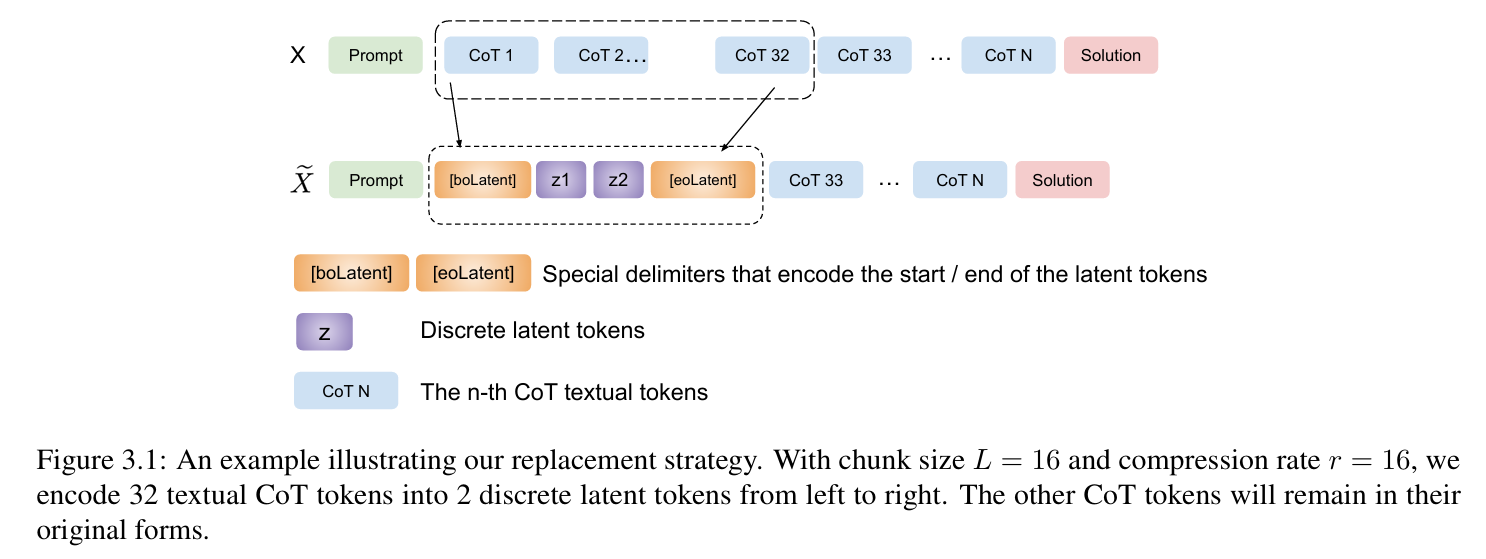
Token Assorted: Mixing Latent and Text Tokens for Improved Language Model Reasoning
Purshow Review
One question I'm concerned about is whether the use of discrete THINKING embedding is detrimental to fine-grained reasoning, and I think it should be validated on the current high-stakes MATH dataset.

Training Large Language Models to Reason in a Continuous Latent Space
Purshow Review
Very interesting exploration, looking forward to further experimenting on LLM with a larger size.
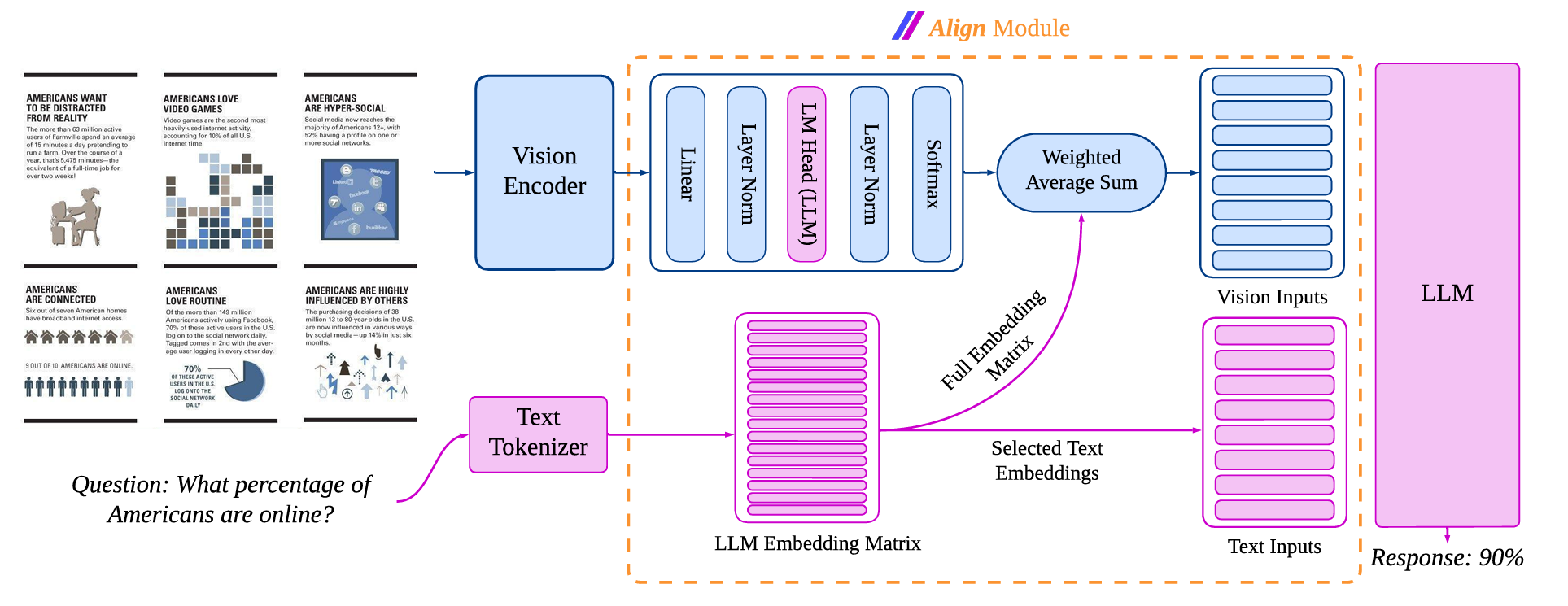
AlignVLM: Bridging Vision and Language Latent Spaces for Multimodal Understanding
SOTA Review
Yuwei is scooped by this paper, but I think the design of embedding metrix is quite reasonable for future modality interaction.
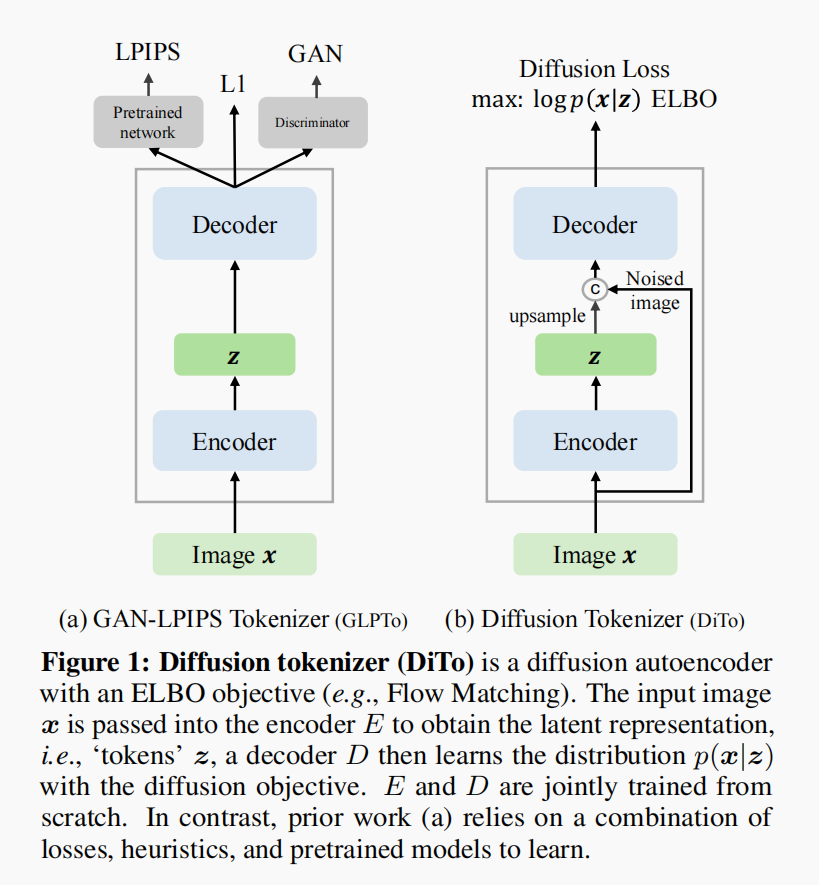
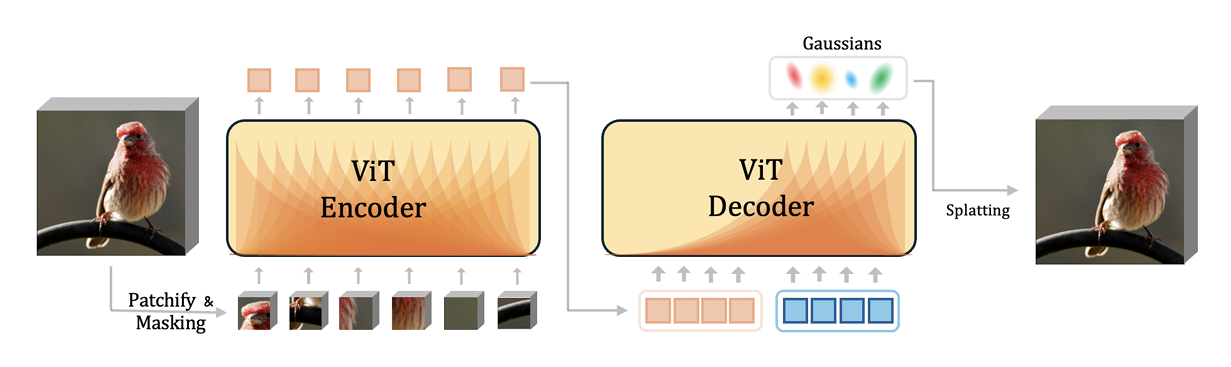
Diffusion Autoencoders are Scalable Image Tokenizers
Purshow Review
A novel image tokenization method using diffusion models. Simple yet effective.
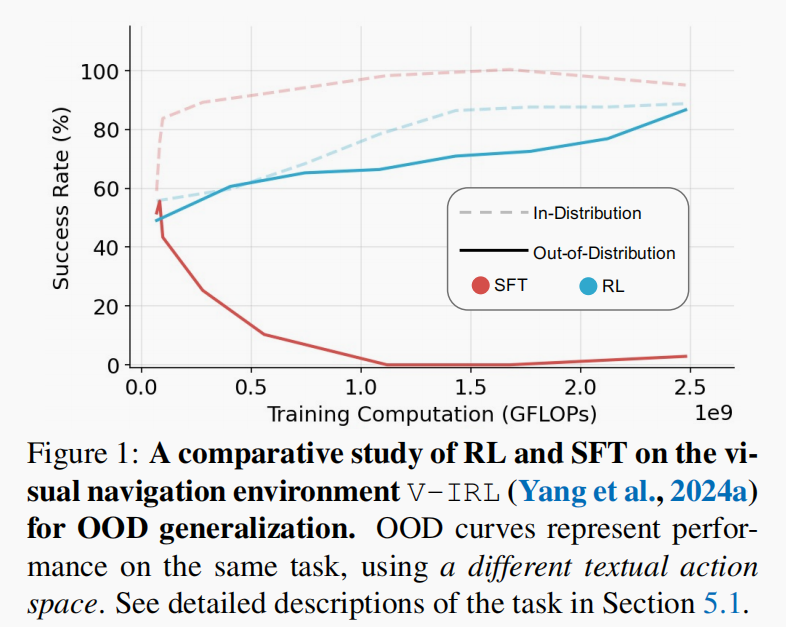
SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training
Purshow Review
This paper effectively contrasts RL and SFT, demonstrating RL's superior generalization capabilities and highlighting SFT's tendency to memorize training data rather than generalize. I think it would be very interesting to explore more scenarios.
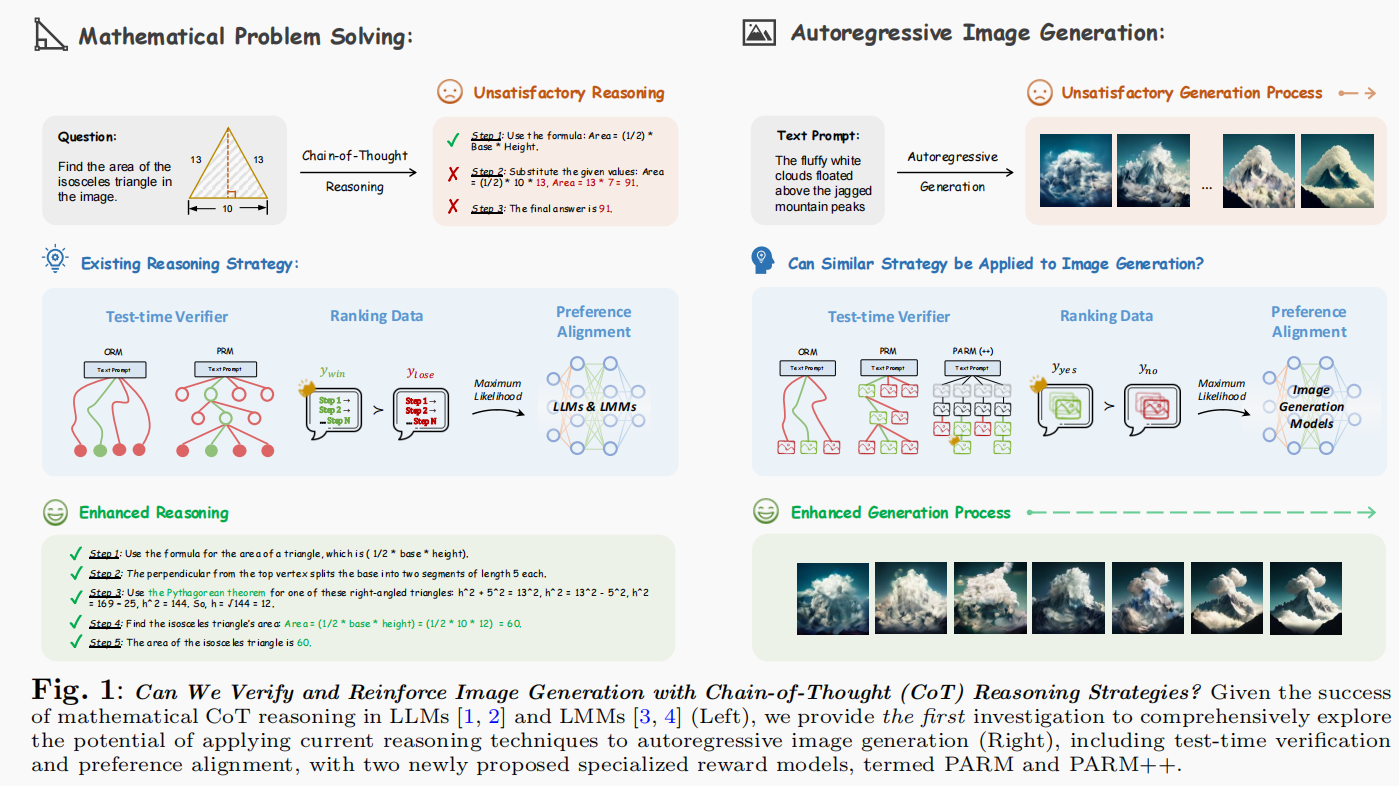
Can We Generate Images with CoT? Let’s Verify and Reinforce Image Generation Step by Step
Purshow Review
A first exploration of cot image generation in "mask AR". Some problems are worth further exploration: 1. Adapt the method to more models, even normal AR models instead of mask AR, 2. Suitable benchmarks that truly test the model's cot benefits 3. Potential for unifying with AR understanding COT
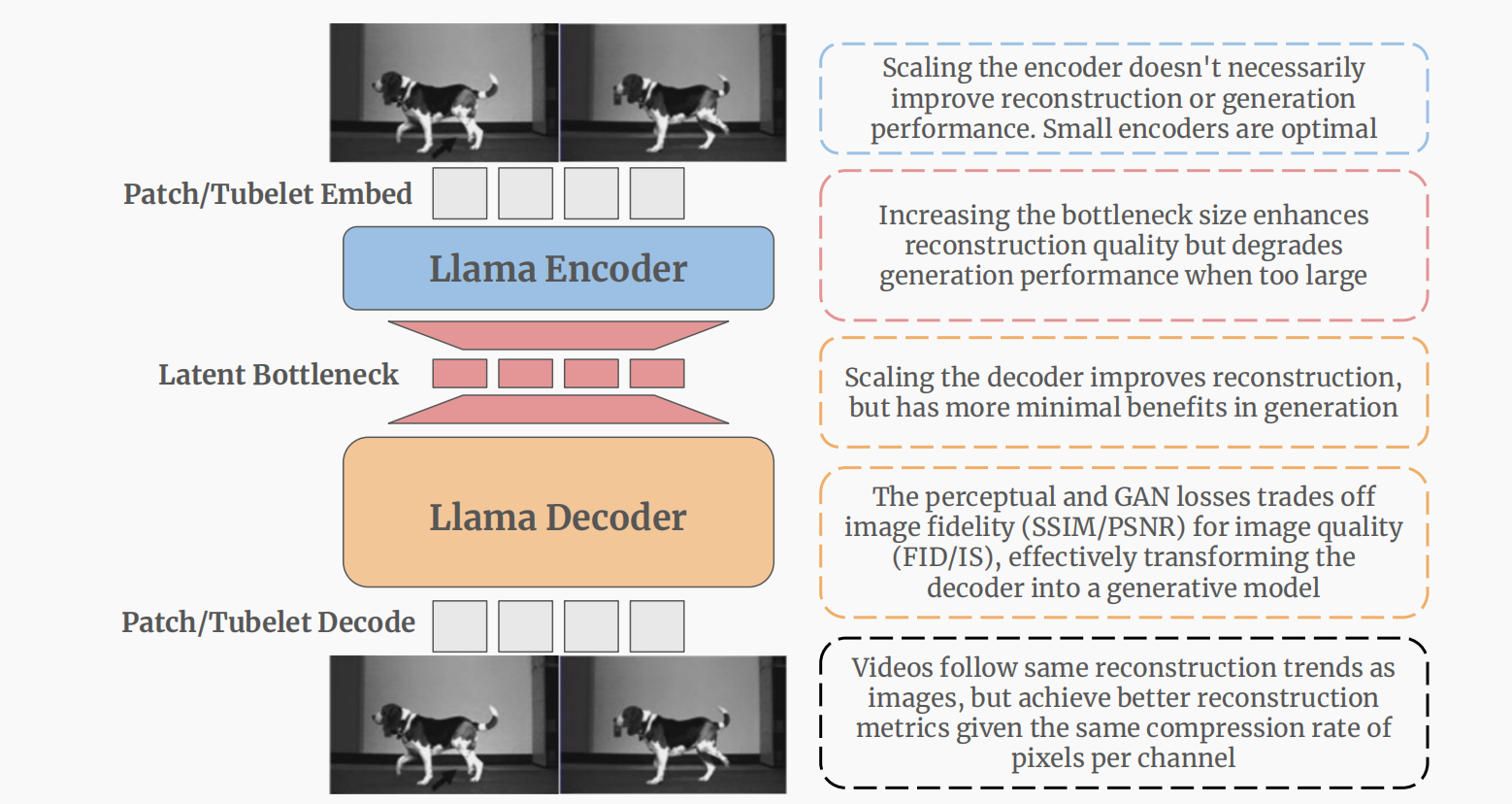
Learnings from Scaling Visual Tokenizers for Reconstruction and Generation
Purshow Review
An exploration of scaling in auto-encoders.
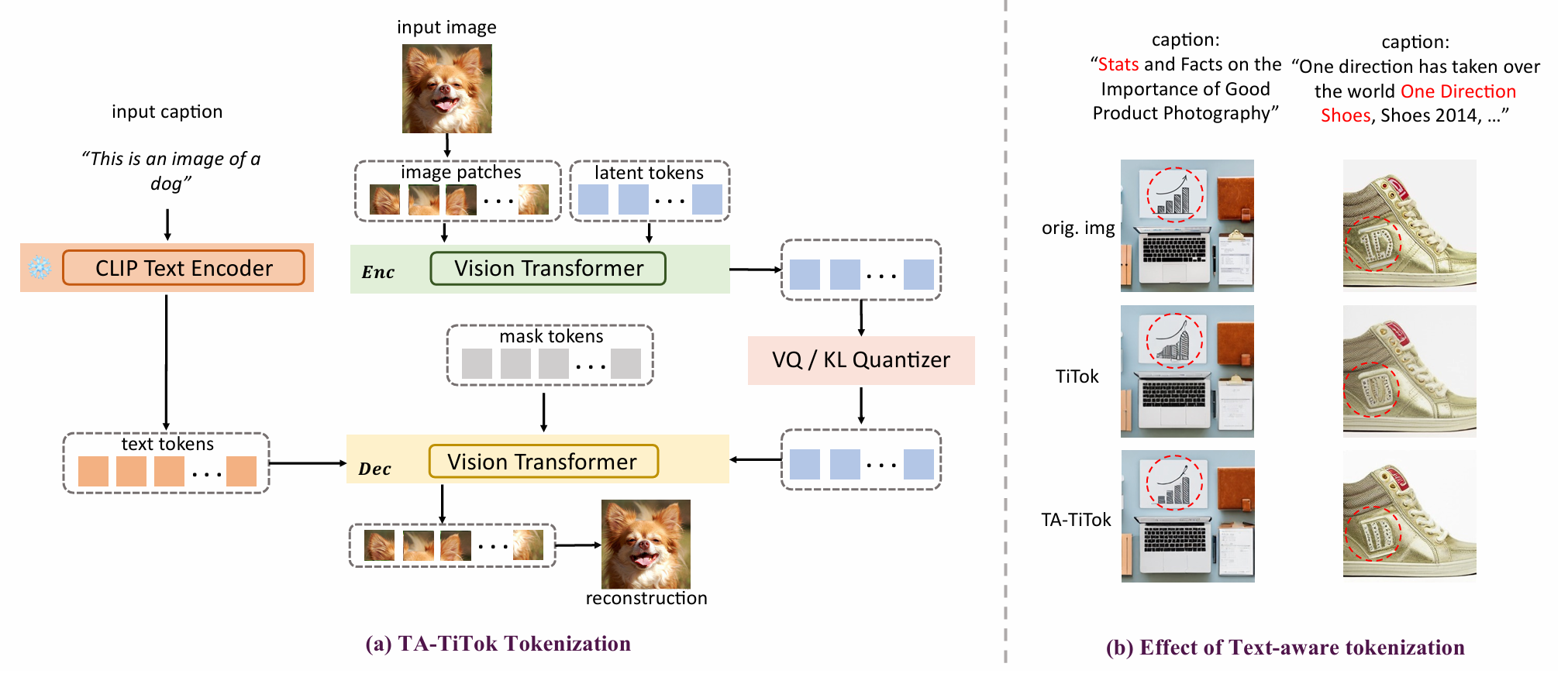
Democratizing Text-to-Image Masked Generative Models with Compact Text-Aware One-Dimensional Tokens
SOTA Review
Integrates textual information during the tokenizer decoding stage (i.e., de-tokenization), accelerating convergence and enhancing performance.
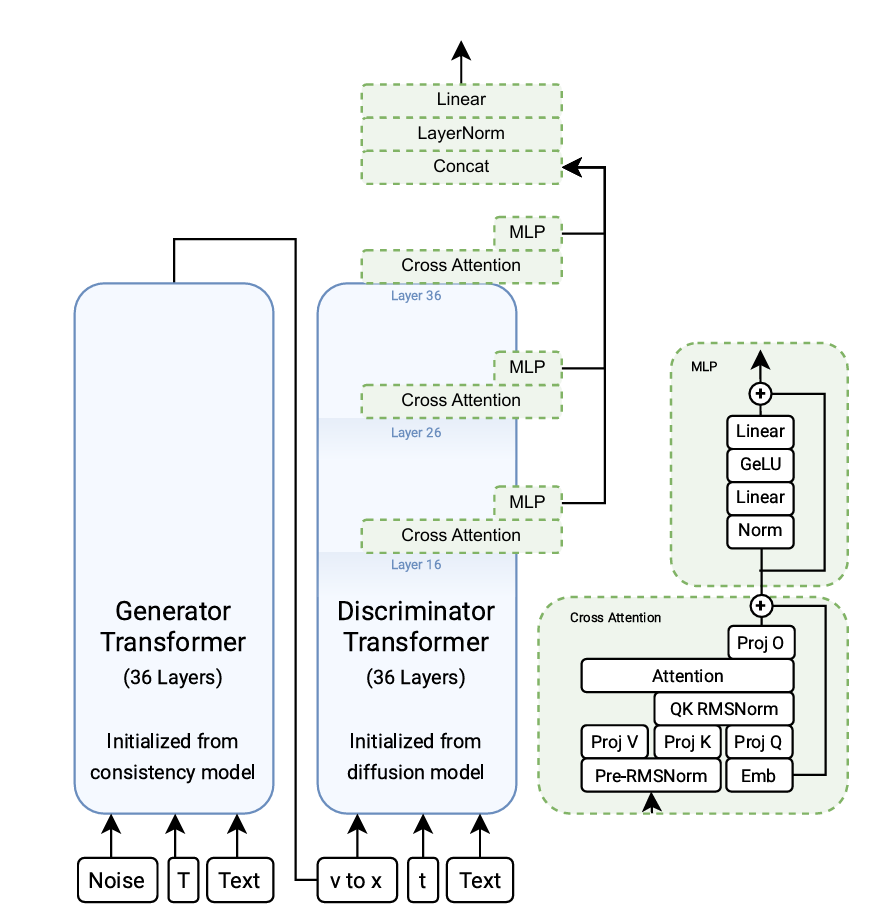
Diffusion Adversarial Post-Training for One-Step Video Generation
SOTA Review
DiT as GAN achieves one-step generation in video.

GameFactory: Creating New Games with Generative Interactive Videos
SOTA Review
By learning motion controls from a small-scale first-person Minecraft dataset, this framework can transfer these control capabilities to open-domain videos.
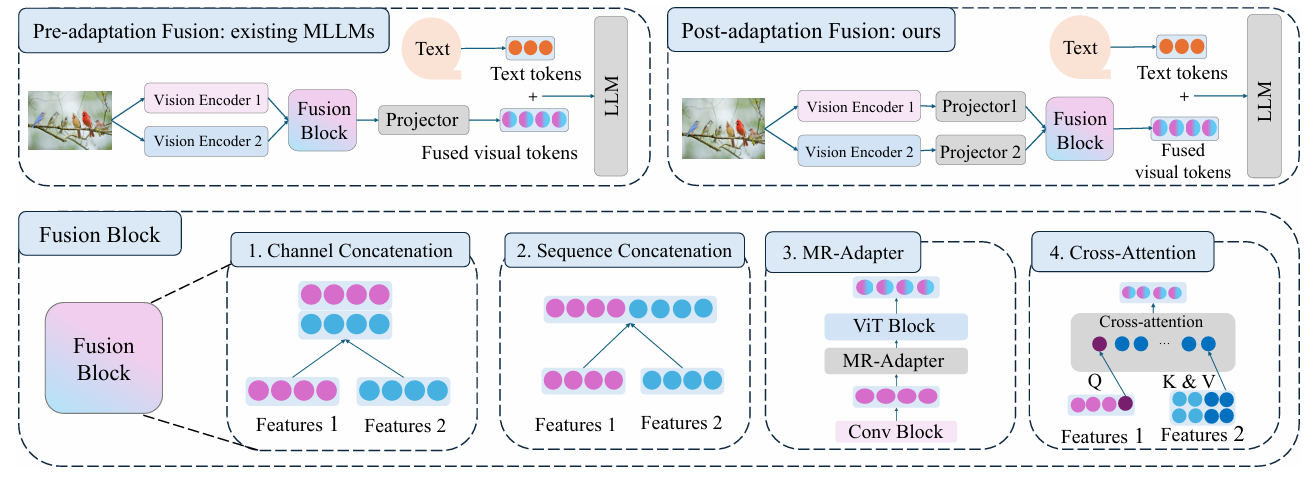
LEO: Boosting Mixture of Vision Encoders for Multimodal Large Language Models
SOTA Review
Feature fusion in MLLMs for MoE vision encoder, should be scaling to make stonger conclusions.
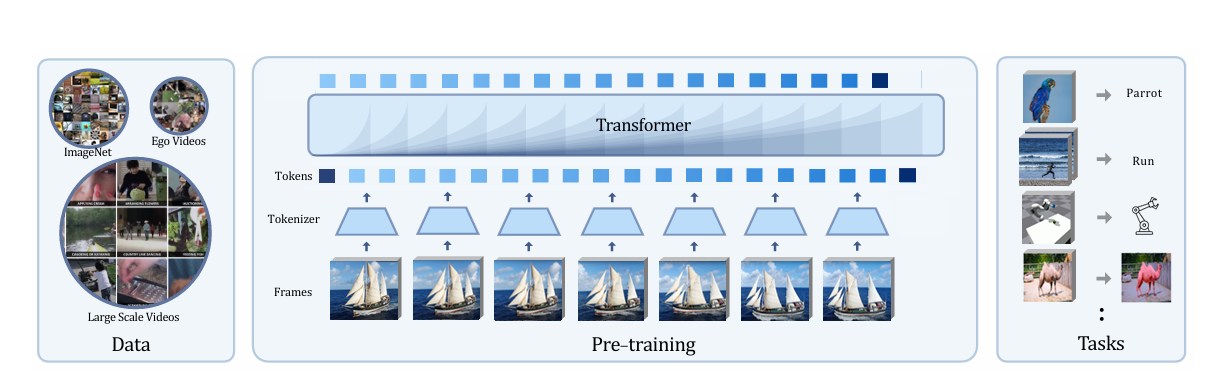
An Empirical Study of Autoregressive Pre-training from Videos
SOTA Review
Pretrain on video using generative method, although performance is not good enough, but it's a good try.
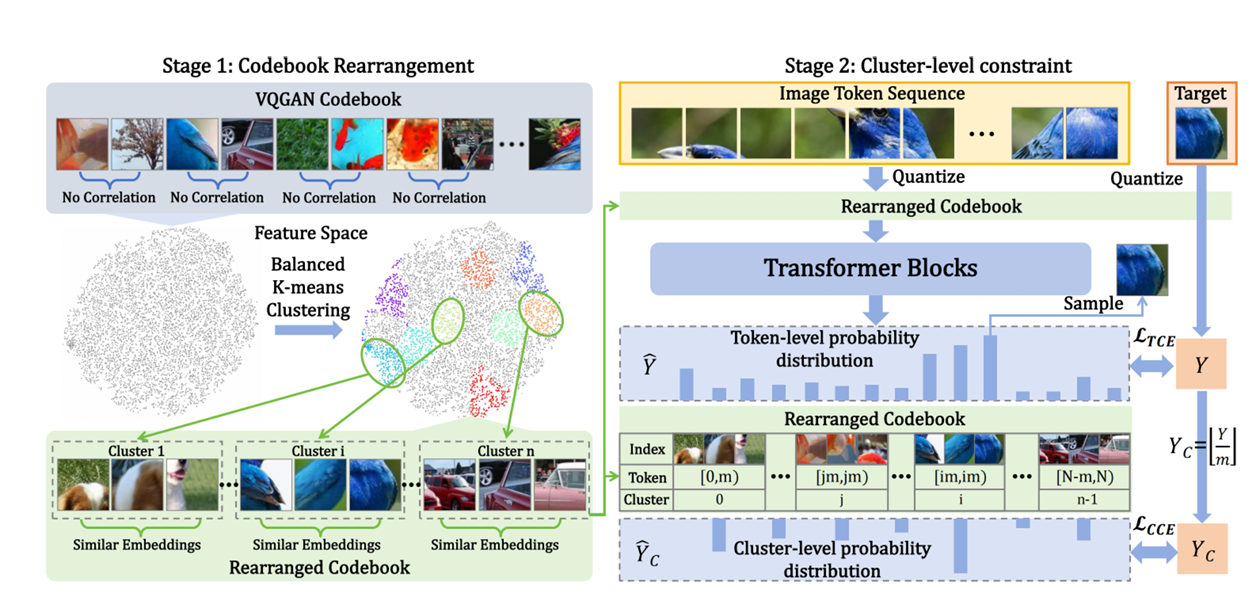
Improving Autoregressive Visual Generation with Cluster-Oriented Token Prediction
SOTA Review
I think semantic-level token clustering is a good attempt in AR image generation. LCM has tried sentence-level generation in AR language generation. Perhaps instead of simple clustering, people can try to do something similar in image?
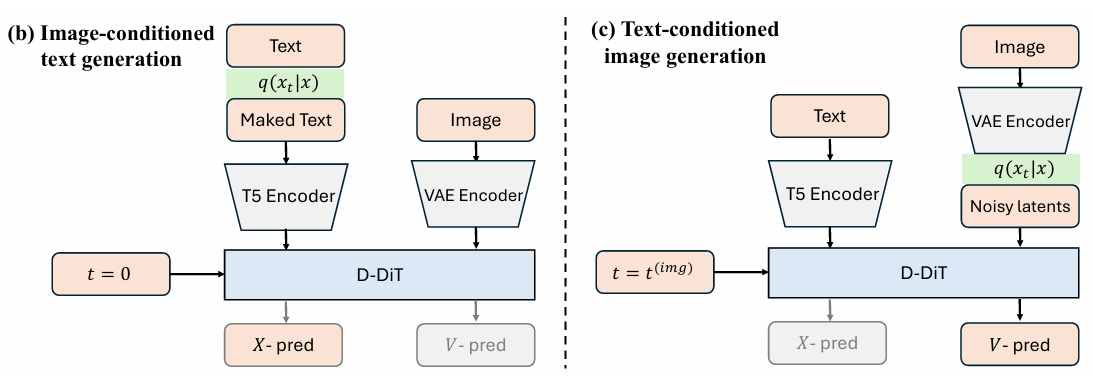
Dual Diffusion for Unified Image Generation and Understanding
SOTA Review
Unified understanding and generative model but using generative model (DiTs) as backbone.
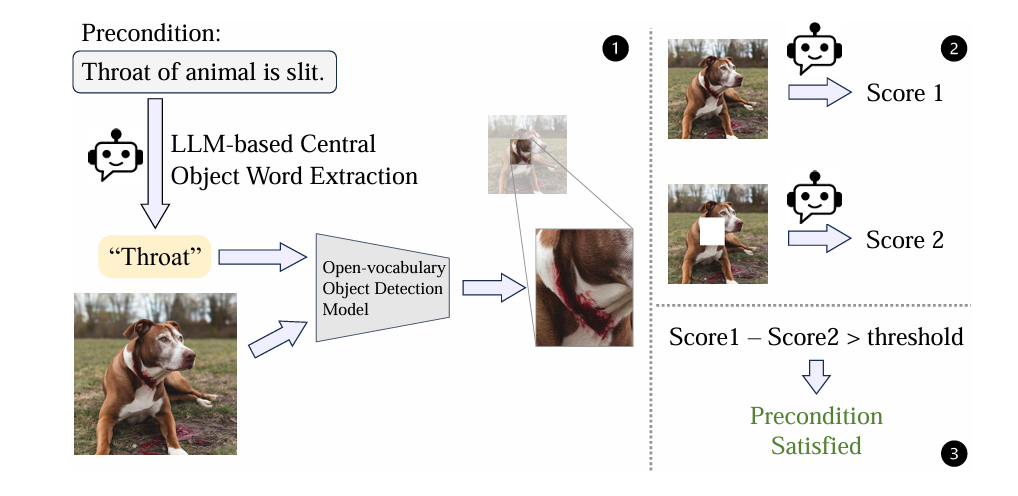
MLLM-as-a-Judge for Image Safety without Human Labeling
SOTA Review
LLM-as-judge is already very common in the field of language models. There was a version of MLLMs before, but not solid enough. I think the bar for this kind of research is very low, but it is difficult to dig deeper. This paper is able to bring up some interesting points such as context bias in images.
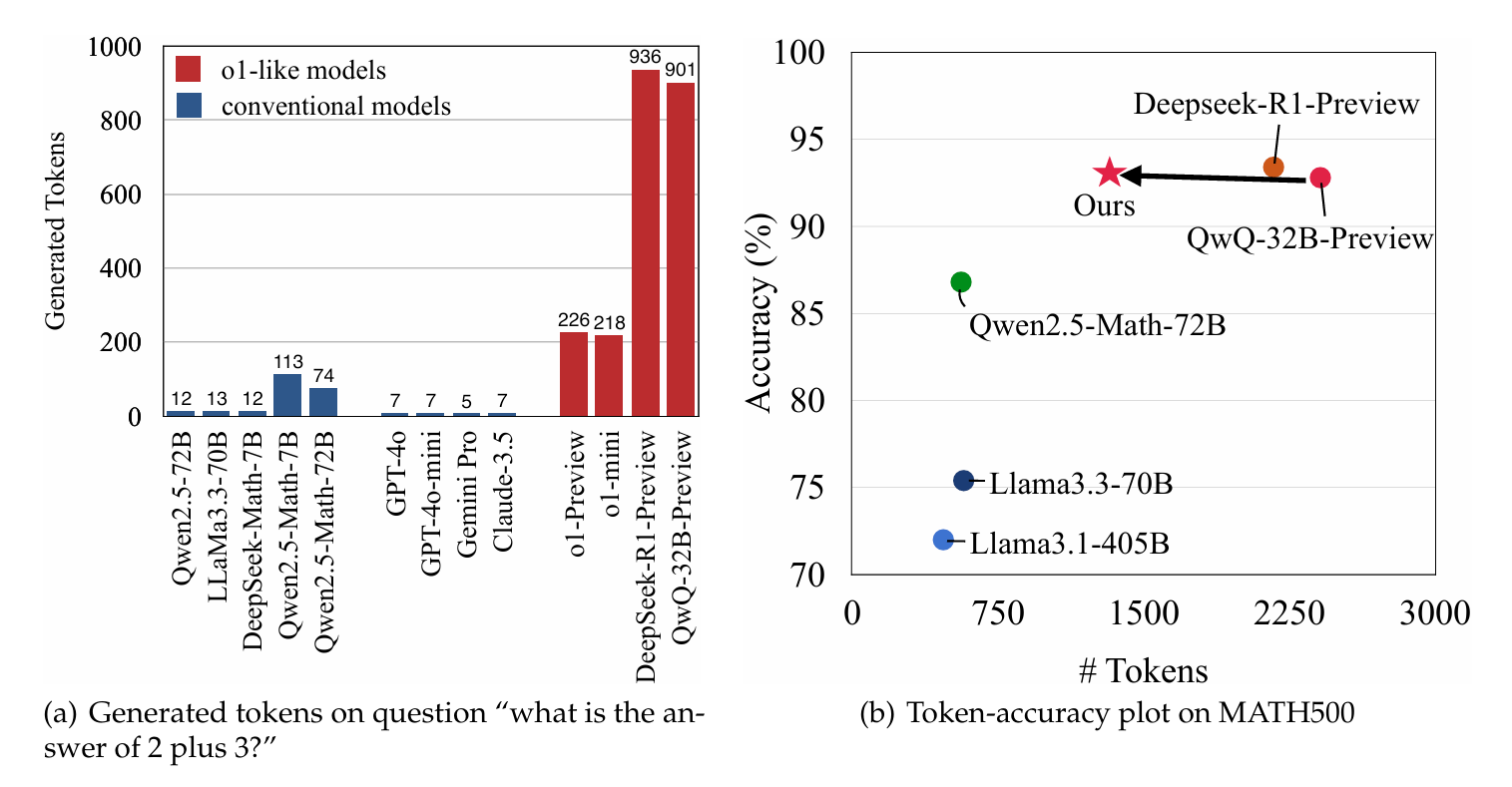
Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs
SOTA Review
Good findings, bad methods.
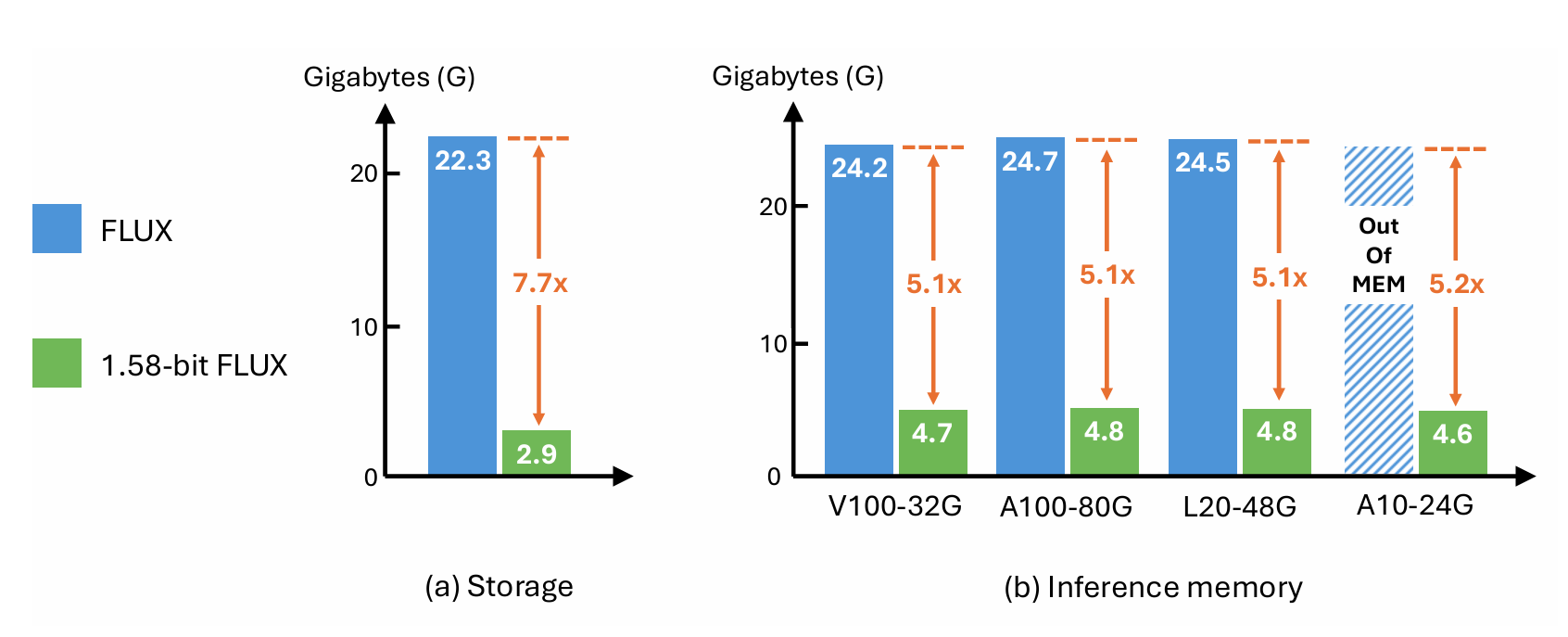
1.58-bit FLUX
SOTA Review
MLsys is important! But the details are not enough to comment and not open source.
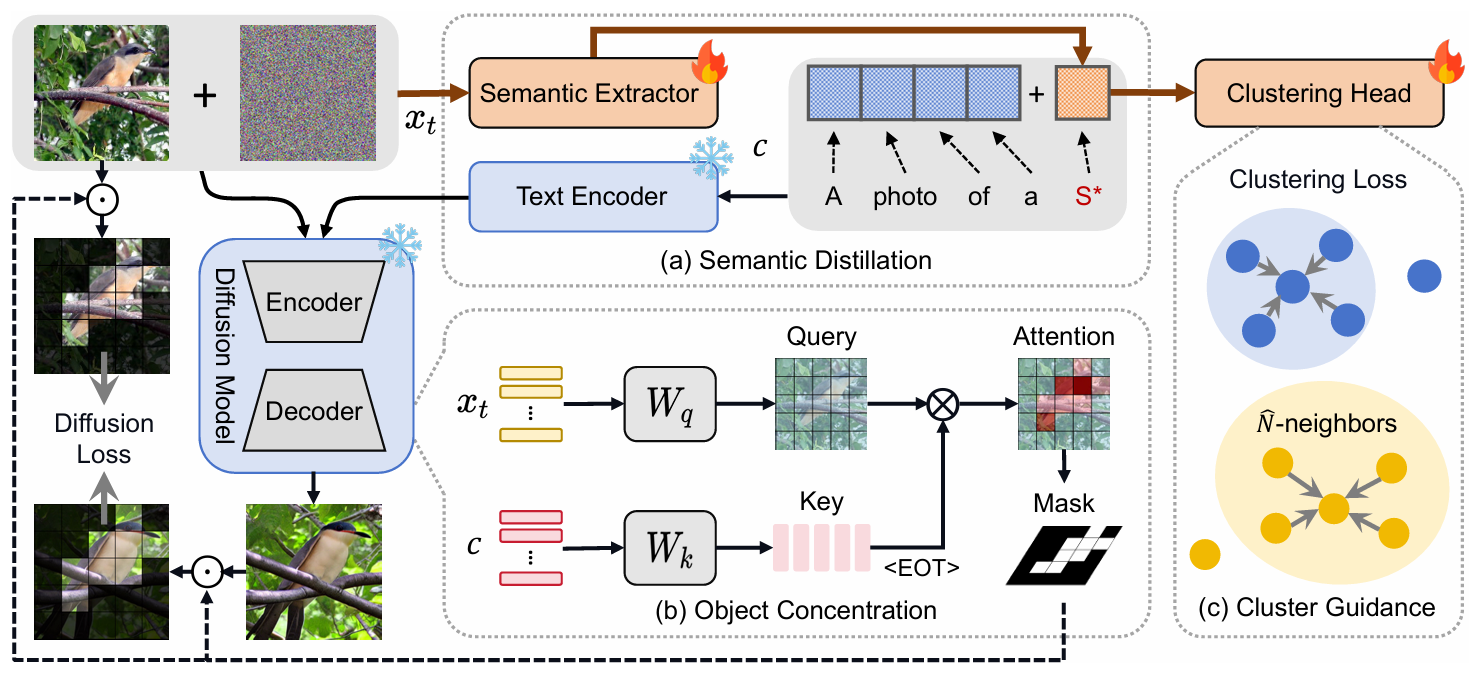
DiFiC: Your Diffusion Model Holds the Secret to Fine-Grained Clustering
SOTA Review
Using the potential discrimination ability of DMs for fine-grained clustering.I think this work is worth expanding, especially since there are similar papers that explore the classification ability of DMs (although it is a coarse classification). It also further illustrates the potential of using generative models for representation learning.
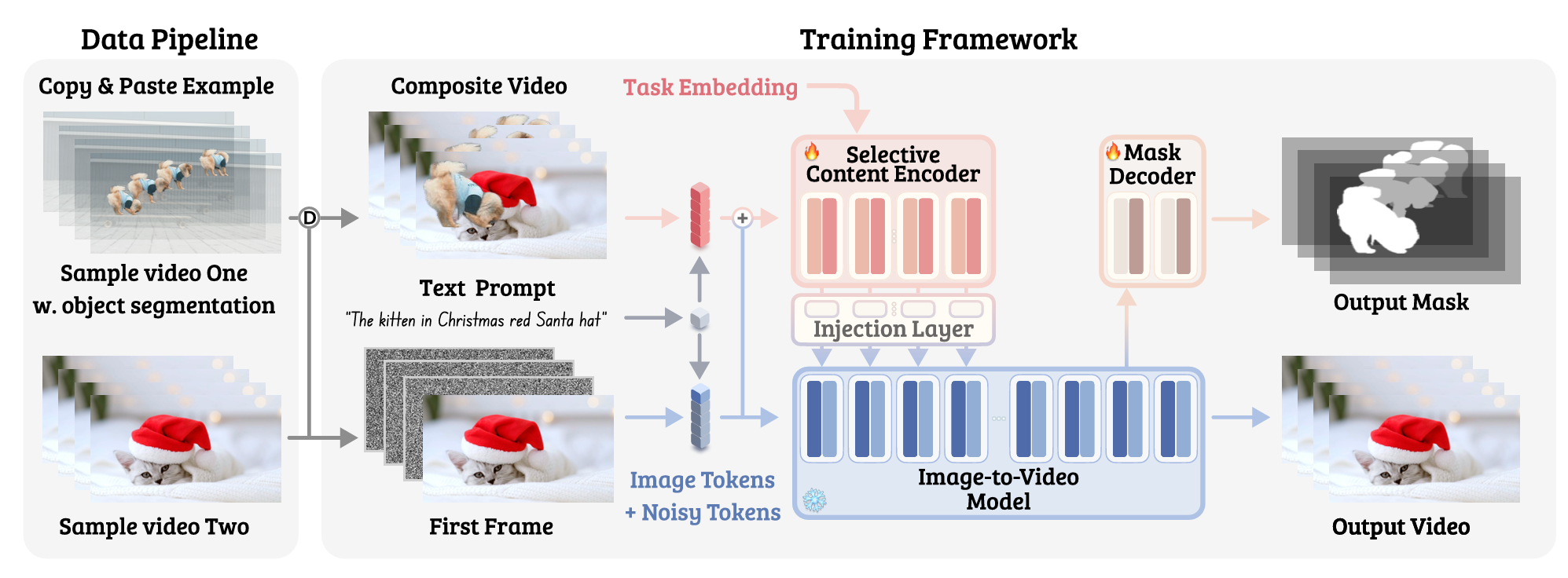
Generative Video Propagation
SOTA Review
A magical framework that uses artificial data to promote related tasks. A strong counterexample constraint is given to be the learning objective. I think there is a certain potential to use it in motion or more implicit control references.
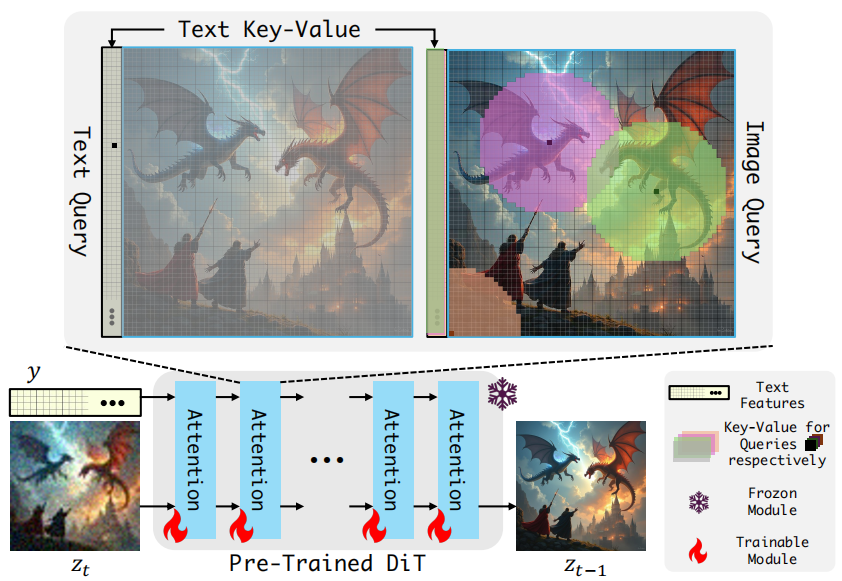
CLEAR: Conv-Like Linearization Revs Pre-Trained Diffusion Transformers Up
SOTA Review
The locality improvement based on conv is definitely helpful to transformer, and the introduction into DiTs is also an inevitable trend. This paper is worth learning from because it is well written (clear motivation and method), and the code maintenance is also worth learning.
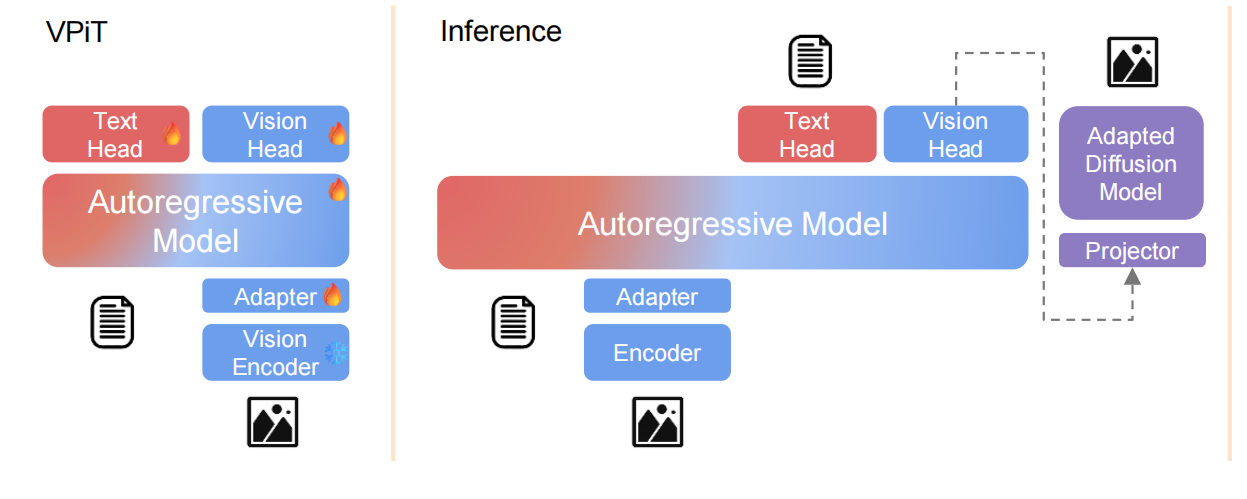
MetaMorph: Multimodal Understanding and Generation via Instruction Tuning
SOTA Review
This paper reveals how generation and understanding can be empirically proven to promote each other. At the same time, I noticed that the features of VIT encoder are very powerful and our existing fine-tuning methods have not fully utilized them.
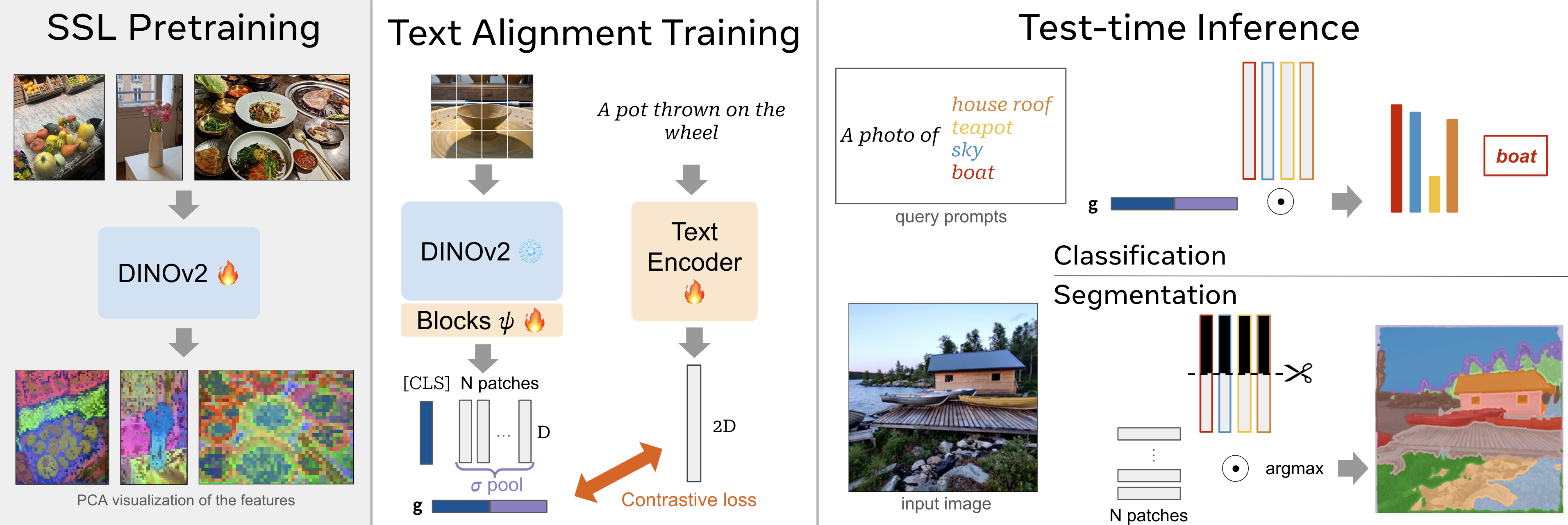
DINOv2 Meets Text: A Unified Framework for Image- and Pixel-Level Vision-Language Alignment
SOTA Review
Simple but effective. The combination of language supervised and unsupervised SSL. I think it is good idea to test on MMVP.
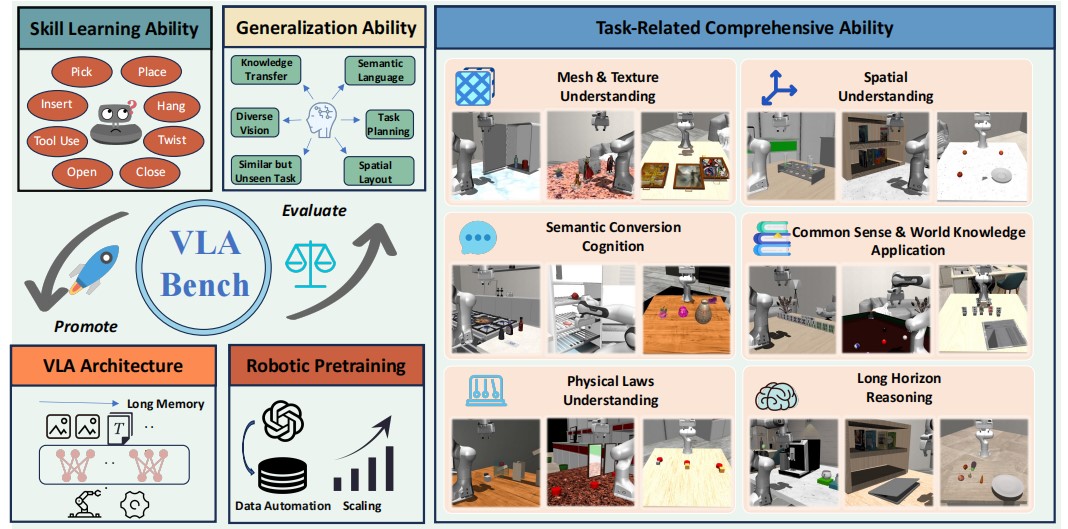
VLABench: A Large-Scale Benchmark for Language-Conditioned Robotics Manipulation with Long-Horizon Reasoning Tasks
SOTA Review
General benchmark for vla, not really impressive, but can be referenced in the future design.

